Pendants to Pipelines: A Computational Toolkit for Khipu Research
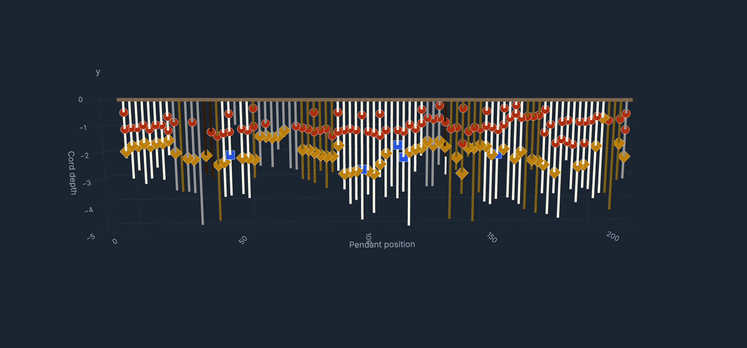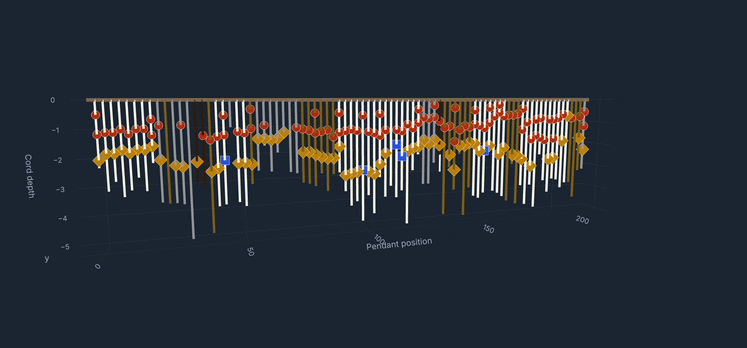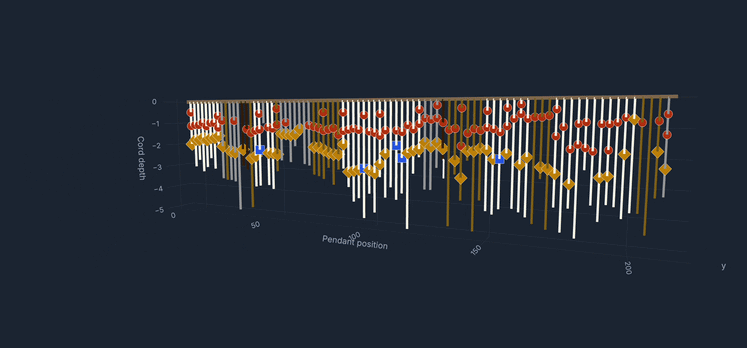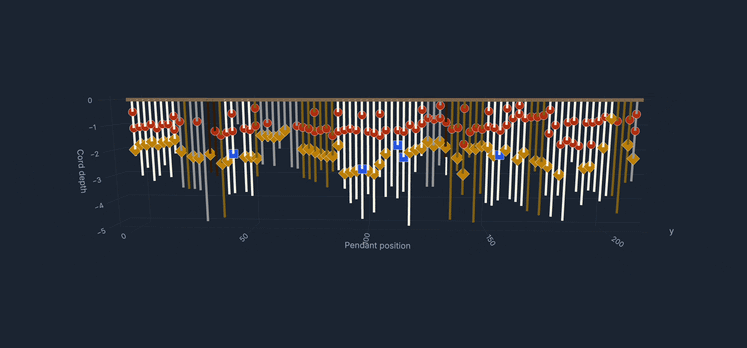
During my upbringing in Peru, khipus consistently captured my attention; these notable knotted cords functioned as the principal medium of recordkeeping for the Inka and earlier Andean cultures. As an adult working in data science, I found myself returning to them with a different kind of curiosity: not archaeological or interpretive, but operational. Could the computational tools I work with every day be useful to the scholars who study these objects?
That question sat with me for a long time. The foundational work of Marcia and Robert Ascher — who helped disseminate knowledge of the positional-decimal conventions for reading khipu knot values (originally put forth by L. Leland Locke) and who documented early systematic evidence of arithmetic relationships — made it possible to ask computational questions about khipus in a rigorous way (see Ascher & Ascher, 1981).
Building on that foundation, the work of Medrano and Khosla (2025) was particularly influential for me. Their large-scale computational analysis provided compelling evidence that internal arithmetic summation structures are a widespread feature of many khipus — a finding that gave me a clearer sense of what a rigorous computational approach to this corpus might look like, and what it might contribute. What it left me with was a much more modest and personal question: could I operationalize that kind of analysis into a reproducible pipeline — the kind I work with every day — as a way of engaging more deeply with the complexity of khipus, and perhaps making that engagement useful to others?
The Khipu Computational Analysis Toolkit (K-CAT) is my attempt at an answer. It is an open-source Python framework for the computational analysis of khipu corpora, built around the two largest available scholarly datasets. It does not claim new findings. It does not attempt to decipher or translate khipus. What it tries to do is make a certain kind of analysis more operationalized and reproducible — a small building block that others might adapt, critique, or extend.
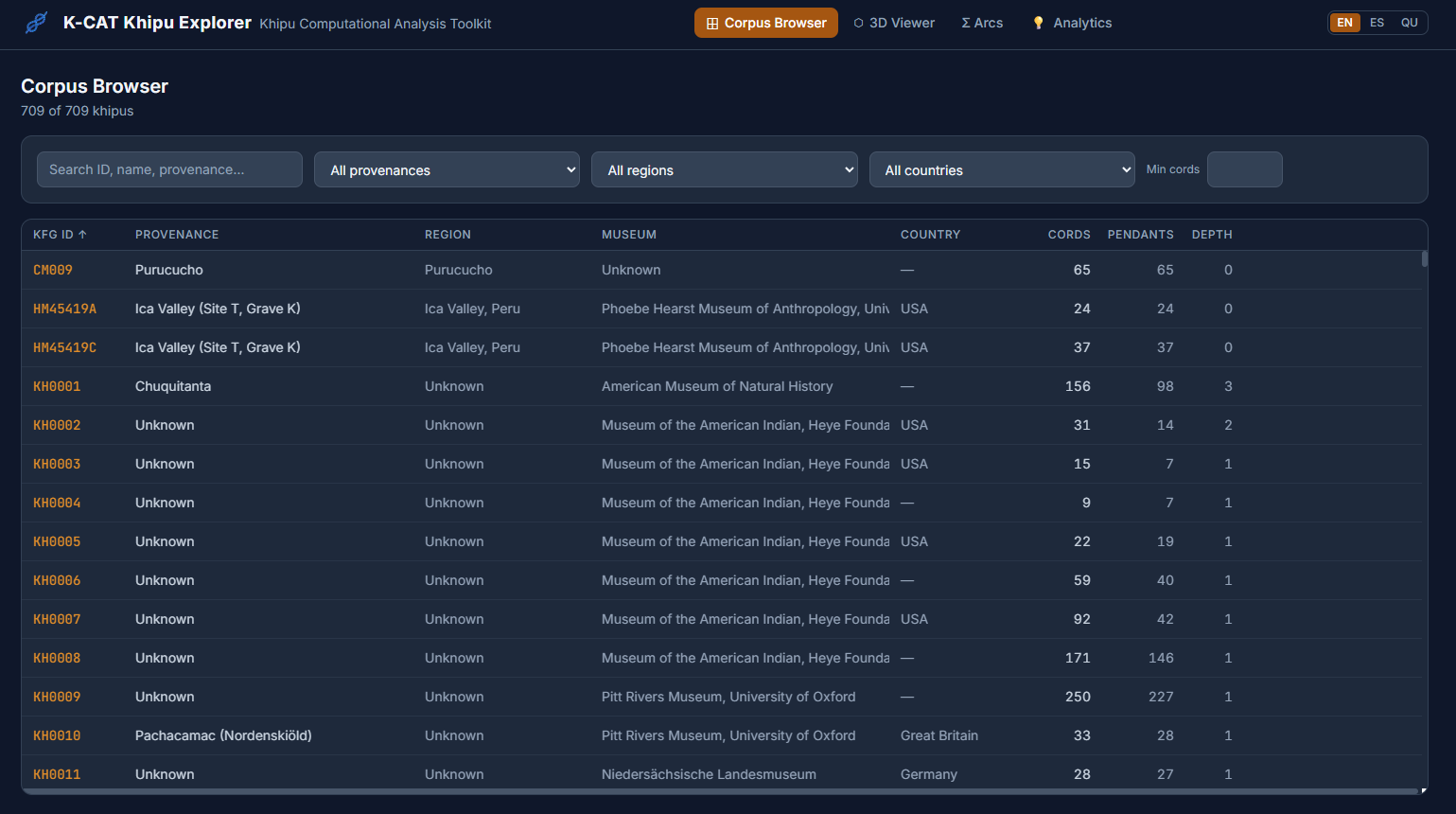
The Datasets
The toolkit is built around two authoritative khipu resources. The Open Khipu Repository (OKR) is an open-access scholarly database overseen by an Advisory Board of scholars. The dataset itself is administered by Mackinley FitzPatrick, and its SQLite dataset contains 612 khipus, 54,403 pendant cords, and 110,677 knots. The KCT uses the OKR as a reference baseline and for certain comparative analyses, but all primary analytical work is grounded in the second resource.
The Khipu Field Guide (KFG), created by Ashok Khosla and the KFG Team, starting in 2020, was originally seeded by the OKRs dataset and has grown to include an array of novel khipu data resources, including human readable khipu datasheets, accessible 2D khipu schematics, and this very blog. Its source format is a set of Excel spreadsheets, which the K-CAT ingests and converts into a unified SQLite database for internal processing. The KFG covers 709 khipus and, crucially, includes expert-identified summation pattern annotations at full cord-level resolution across nine distinct arithmetic relationship types. These annotations serve as the “ground truth” against which the toolkit's computational results are measured.
Building from the Ground Up
The first decision was methodological: rather than applying analytical methods to the corpus all at once, the toolkit is organized as a staged pipeline where each phase builds on top of validated outputs from the previous one. This matters because khipu data is complex, partially incomplete, and of variable quality depending on the source. The starting point was simply understanding what the KFG corpus contains — its khipus, cords, knot records, color records, and numeric coverage — and establishing the positional-decimal convention that underpins all numeric decoding downstream. Every value decoded later in the pipeline depends on getting this foundation right.
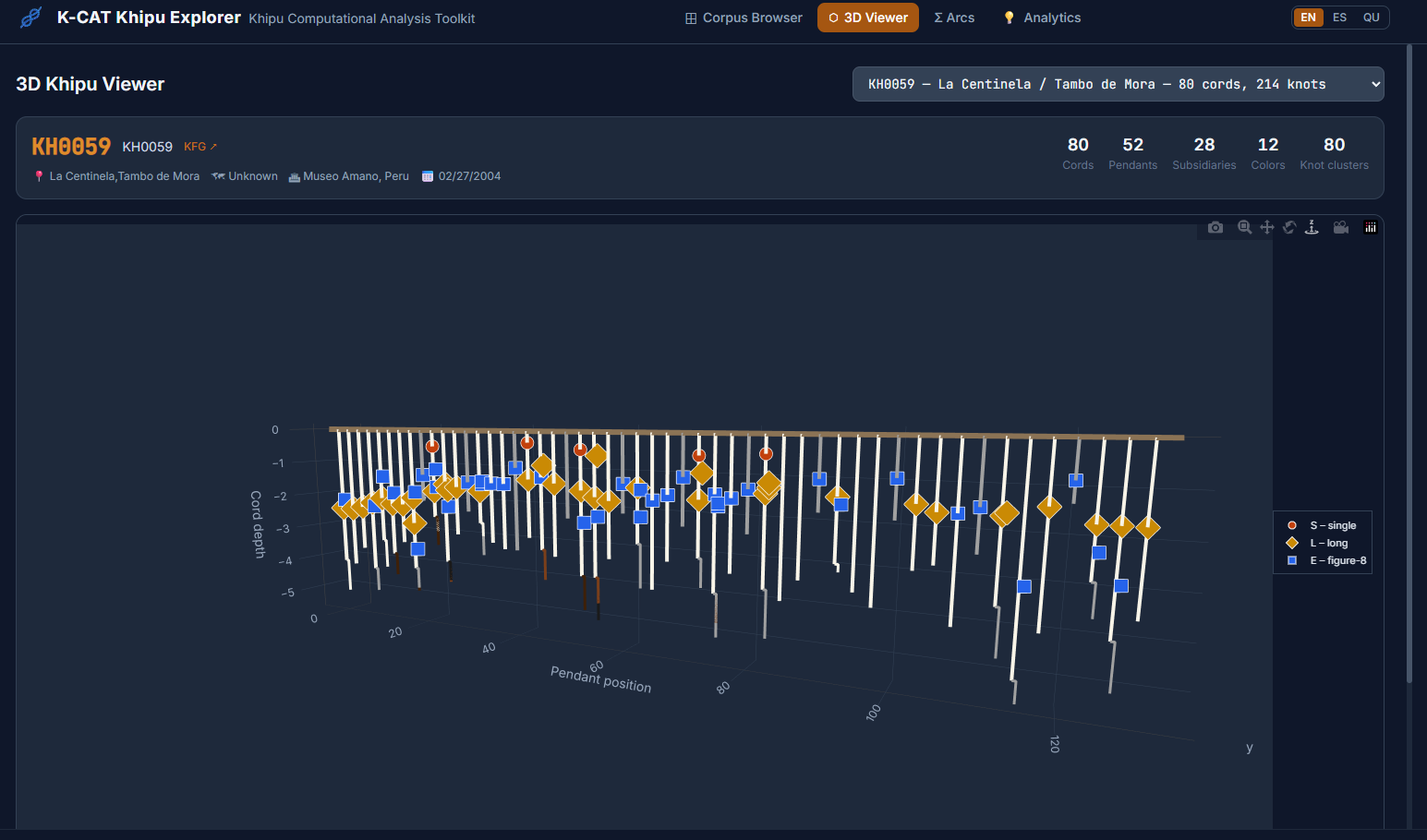
Testing What the KFG Already Knows
With that baseline in place, the most natural first analytical question was the one the KFG's expert annotations already answer: are arithmetic summation structures detectable computationally, and does the detector agree with what the scholars found? The toolkit implements an arithmetic pattern detector that tests, for each of the 709 khipus, whether any cord's value equals the sum of a defined set of other cords — varying by position, color, hierarchy, or group — across eight distinct relationship types. The KFG's annotation files serve as the ground truth, and reconciliation against them drove several rounds of refinement: normalizing compound color codes so that color-equality comparisons work correctly, and tightening detection criteria for the pattern types that initially over-detected. But perhaps where the analysis becomes most interesting is in areas that extend beyond the current reach of the vast KFG corpus.
From Patterns to Questions
Once the summation detection layer was stable, the pipeline extended into territory that feels more genuinely exploratory. The toolkit now includes a full analytics layer built on KFG-native sources: per-pattern prevalence across the corpus, pattern-complexity distributions showing how many simultaneous summation types individual khipus carry, and a provenance breakdown mapping which patterns cluster at which Andean sites.
That last piece connects to what feels like one of the more interesting questions the toolkit can help frame: are specific summation patterns geographically concentrated in known administrative centers, or do they appear more broadly across the Andean landscape? The KFG has richer and more accurate provenance metadata than earlier datasets, which makes this kind of spatial analysis possible in a way it wasn't before. The toolkit also runs structural clustering on the KFG corpus — grouping khipus by cord geometry and hierarchy, deliberately excluding summation features so they don't dominate the solution — and then cross-references cluster membership with pattern presence. The question behind that analysis is whether khipus that look structurally similar also tend to share recording conventions, or whether structure and arithmetic behavior are largely independent.
These are hypotheses to explore, not conclusions to announce. But having the infrastructure to test them reproducibly, and to revisit them as the field's understanding evolves, feels like a meaningful contribution to make.
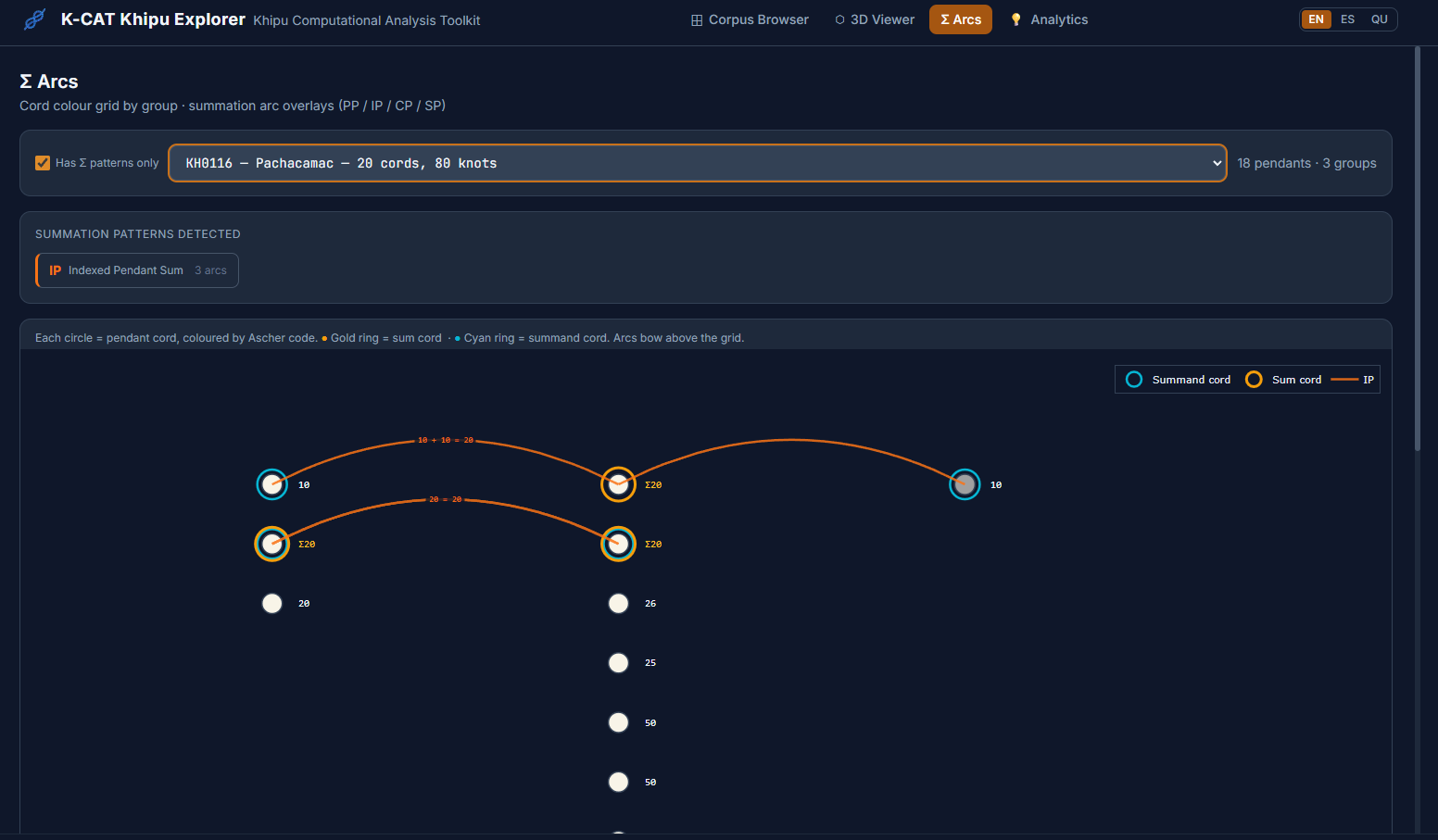
The Browser
All of this feeds into an interactive local browser that makes the corpus explorable without requiring any programming. A filterable table gives access to all 709 KFG khipus with provenance, region, museum, and cord-count information, with direct links to each khipu's page on the Khipu Field Guide website. A 3D viewer renders the full cord hierarchy for any selected khipu, colored by Ascher color codes, with hover tooltips showing cord name, color, decoded value, and knot data. A Summation Arcs view presents every pendant cord as a colored grid organized by group and position, with a summary table of group-level statistics.
A cloud-hosted version of the application, which makes this accessible without a local installation, is fully deployed and at https://khipu-explorer.greenrock-570e1f4a.westus2.azurecontainerapps.io/.
What This Is Not
It would be easy to overstate what a toolkit like this can offer, and I want to be careful not to. Computational pattern detection can tell us that certain arithmetic relationships are present at certain rates — it cannot tell us what those relationships meant to the people who created and used khipus. Structural clustering can identify groups of khipus that resemble each other — it cannot tell us whether those groups correspond to any administratively or culturally meaningful category. The geographic analysis can surface spatial concentrations of certain patterns — it cannot explain them. That interpretive work remains the domain of scholars with deep expertise in Andean history, archaeology, and material culture, and I hold the toolkit outputs accordingly.
An Invitation
The question I started with — whether the tools I know could contribute something useful to this field — still feels genuinely open to me. I hope the toolkit is a small step toward answering it, but whether it proves useful is something only the research community can judge. I offer it in that spirit.
The Khipu Computational Analysis Toolkit is open-source and available at https://github.com/adafieno/khipu-computational-toolkit under an MIT license. I welcome feedback, critiques, and suggestions from anyone in the khipu research community — particularly regarding cases where the computational approach misrepresents or oversimplifies the underlying data. If someone with deeper domain expertise sees something in these outputs worth pursuing, or something worth correcting, I would be genuinely grateful to hear it.
References
Ascher, Marcia, and Robert Ascher. 1981. Code of the Quipu: A Study in Media, Mathematics, and Culture. University of Michigan Press.
Medrano, Manuel, and Ashok Khosla. 2024. “How Can Data Science Contribute to Understanding the Khipu Code?” Latin American Antiquity 36 (2): 497–516. https://doi.org/10.1017/laq.2024.5.
Open Khipu Repository: https://github.com/khipulab/open-khipu-repository
Khipu Field Guide: https://www.khipufieldguide.com

Comments ()