Are Khipus a Written Language?

The Inca Empire ruled without a conventional writing system. Instead, they used khipus, colored cords and knots, to administer their empire. For decades, scholars have debated whether khipus represent a true written language or simply an accounting format. Research over the last few years, using tools from the fields of statistical linguistics[1] and data science [2] offers some compelling insights to the debate.
What Evidence Do We Have That Khipus Encode Language?
We have approximately 100 records of recitations of quipus in a court setting, where a quipu was read, in Quechua, translated to Spanish, and then recorded in the court records.[3] Also known as revisitas, these this recitations show us that quipus recorded censuses of people, goods bought and sold, duties levied and paid, and perhaps a travelogue or two.
However, a count of bushels of quinoa, potatoes, and peanuts, does not constitute a language. In the last 100 years of khipu decipherment, we have made enormous progress on deciphering the numerical sophistication of khipu counting [2:1],[4]. However, we have made extremely little progress linguistically. We still lack even the ability to determine if something is potatoes or peanuts.Is there really language there? Why is it so tough to find?
Let's look at the question using two tools from statistical linguistics.
Three Laws That Allow Us to Measure "Linguisticity"
“linguisticity” (n.) — the degree to which a system exhibits properties characteristic of language
Believe it or not, there are actual linguistic laws. Not laws like "Don't end a sentence with a preposition," but laws like "a word's length depends on how often its used." These laws allow us to measure the "linguisticity" of a set of signs and symbols like a manuscript.[5]
Three useful laws can be applied to our corpus of ~670 khipus in the KhipuFieldGuide. The mathematics behind these laws allow us to measure the "linguisticity" of khipus.
These three laws are:
- Benford's Law - a law about the human use of numbers
- Zipf's Law - a law about the frequency of unique words in a language
- Hapax Legemona - a law (derived from Zipf's Law) about the frequency of rare words in a language
Benford's Law
Benford’s Law by Dan Ma
The first digit (or leading digit) of a number is the leftmost digit (e.g. the first digit of 567 is 5). The first digit of a number can only be 1, 2, 3, 4, 5, 6, 7, 8, and 9 since we do not usually write a number such as 567 as 0567. Some fraudsters may think that the first digits in numbers in financial documents appear with equal frequency (i.e. each digit appears about 11% of the time). In fact, this is not the case. It was discovered by Simon Newcomb in 1881 and rediscovered by physicist Frank Benford in 1938 that the first digits in many data sets occur according to the probability distribution indicated in the figure below:
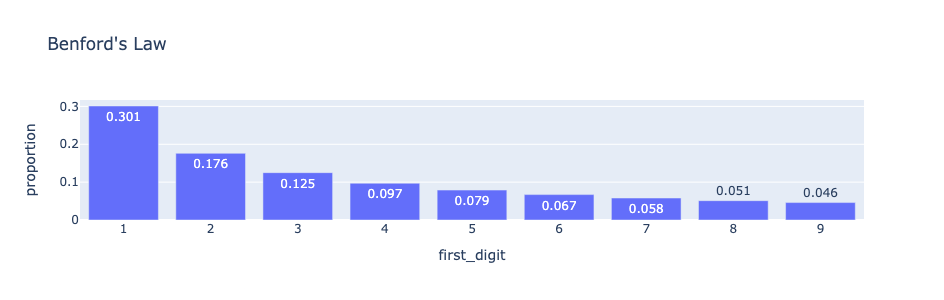
The above probability distribution is now known as the Benford’s law. It is a powerful and yet relatively simple tool for detecting financial and accounting frauds. For example, according to the Benford’s law, about 30% of numbers in legitimate data have 1 as a first digit. Fraudsters who do not know this will tend to have much fewer ones as first digits in their faked data.
Data for which the Benford’s law is applicable are data that tend to distribute across multiple orders of magnitude. Examples include income data of a large population, census data such as populations of cities and counties. In addition to demographic data and scientific data, the Benford’s law is also applicable to many types of financial data, including income tax data, stock exchange data, corporate disbursement and sales data. The author of I’ve Got Your Number How a Mathematical Phenomenon can help CPAs Uncover Fraud and other Irregularities, Mark Nigrini, also discusses data analysis methods (based on the Benford’s law) that are used in forensic accounting and auditing.
What Benford's Law Tells Us
When we apply Benford's Law to khipus, most KFG khipus closely match the distributions found in human accounting records. Even more telling: khipus with low Benford matches show strong Ascher Sum relationships—mathematical patterns where pendant cords are the sum total of a set of other pendant cords. This is exactly what you'd expect from an accounting system, not a written language.
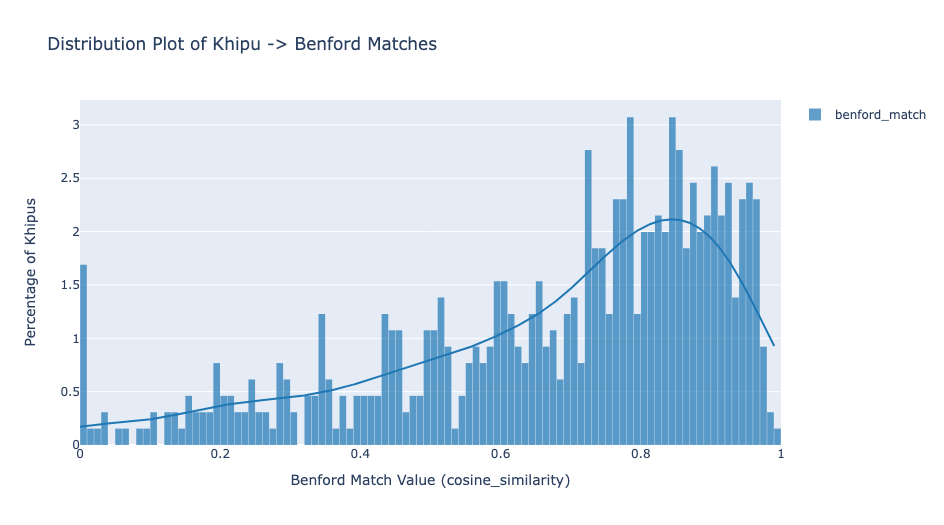
What About low-Benford Match Khipus?
What if khipus were linguistic? If khipus are indeed linguistic, we would expect their cords to take on one of two possible linguistic structures:
-
Linear/Serial Structure: One possibility is that language is encoded serially with each cord expressing a morpheme or word. The Zipf’s Law study below explores this possibility.
-
Tree Structure: The other possibility is that language is expressed in a tree fashion, using primaries and subsidiaries, like the sentence diagrams you used to do in grade school. The Benford’s law Fan-out study below suggests that encoding in a tree fashion is highly unlikely.
Examine this diagram:
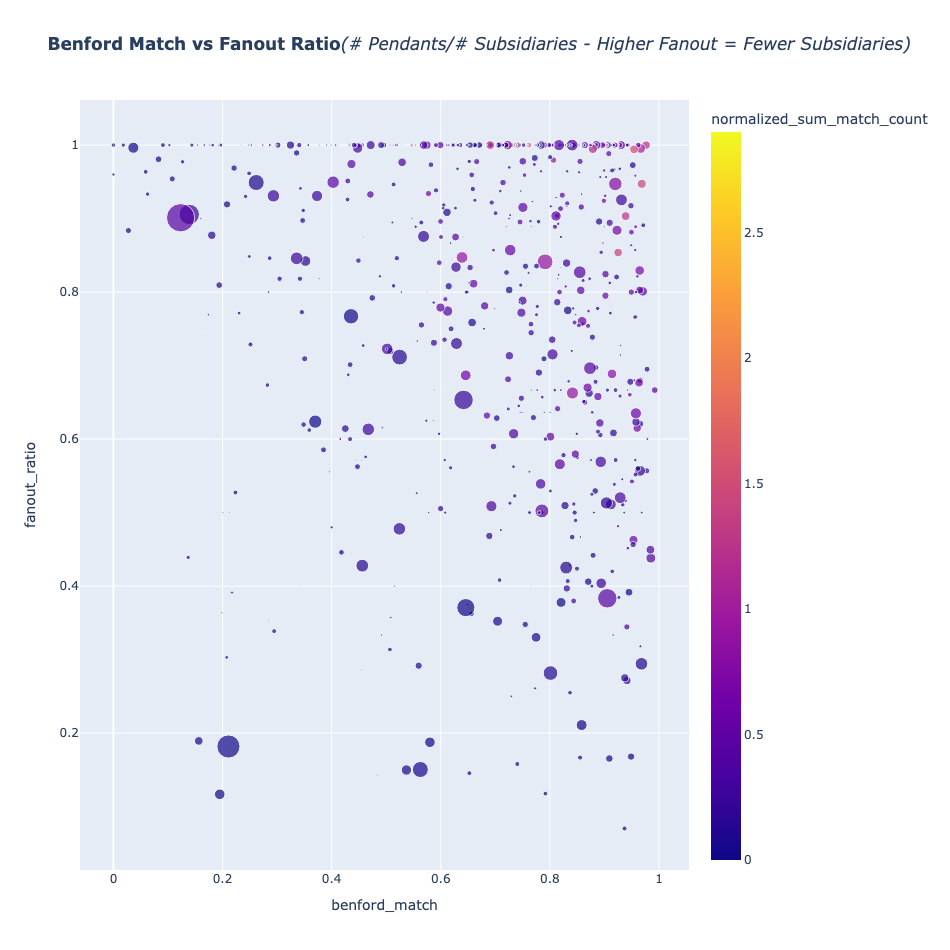
The only significant khipu to appear in the lower left triangle (the likely “linguistic” zone) of the above diagram is KH0329/UR093. However, an examination of this khipu’s Ascher sum relationships shows it to have a significant number of arithmetic sums.
Zipf's Law
Zipf's Law describes how words are distributed in human language—a few words appear very frequently (like "a" and "the"). These words tend to be short in length, and occupy the vast majority of our spoken utterances. Words like utterance occur much more rarely and are typically under 5% of the total words in a conversation or manuscript.
Zipf’s law is an example of what scientists call a power law. Basically it says that the number of times a word occurs in a document, called it’s rank, follows a 1/f distribution. Initially, for example the word a, whose rank is 1, the % it occurs in a document is say 10%. The word the might be 8%, etc., but the word ruminant, will be less than 0.0001% of the overall document.
A classic application of Zipf’s law is to predict the frequency of a word:
as a function of:
- A total document size N (the number of words)
- A ranking k - words, sorted in order, by frequency count
In mathematical terms:
Let:
- N be the number of words (ie. a document’s word count)
- k be their rank (the number of times a particular word occurs in the document)
Zipf’s law then predicts that out of a population of N elements, the normalized frequency of the element of rank k, normalized_freq(k, s=1, N), is:
Power laws, like Zipf's Law, have an interesting property - when graphed on a log-log (x/y) scale, the mathematical result is a line.
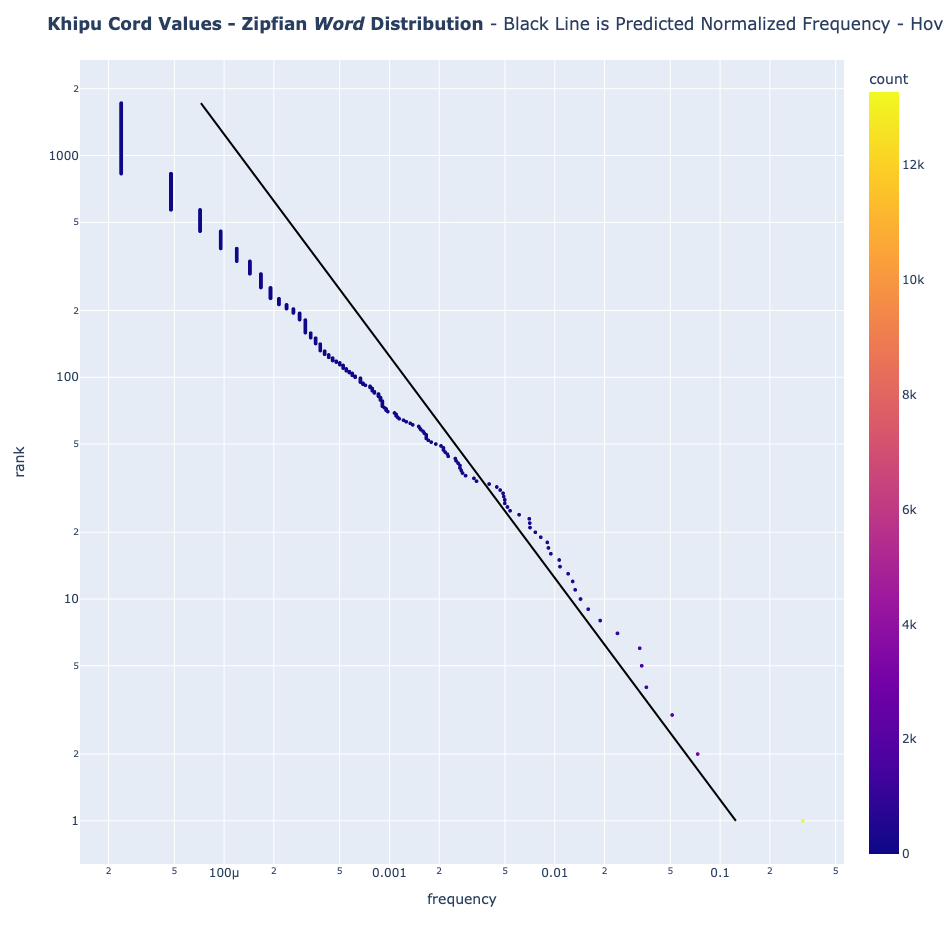
By testing khipus against Zipf's Law, we can determine whether khipu words occur in a frequency curve similar to natural language.
What Zipf's Law Reveals
Here's where the evidence becomes intriguing. I tested Zipf's Law across multiple "languages":
- English (Moby Dick)
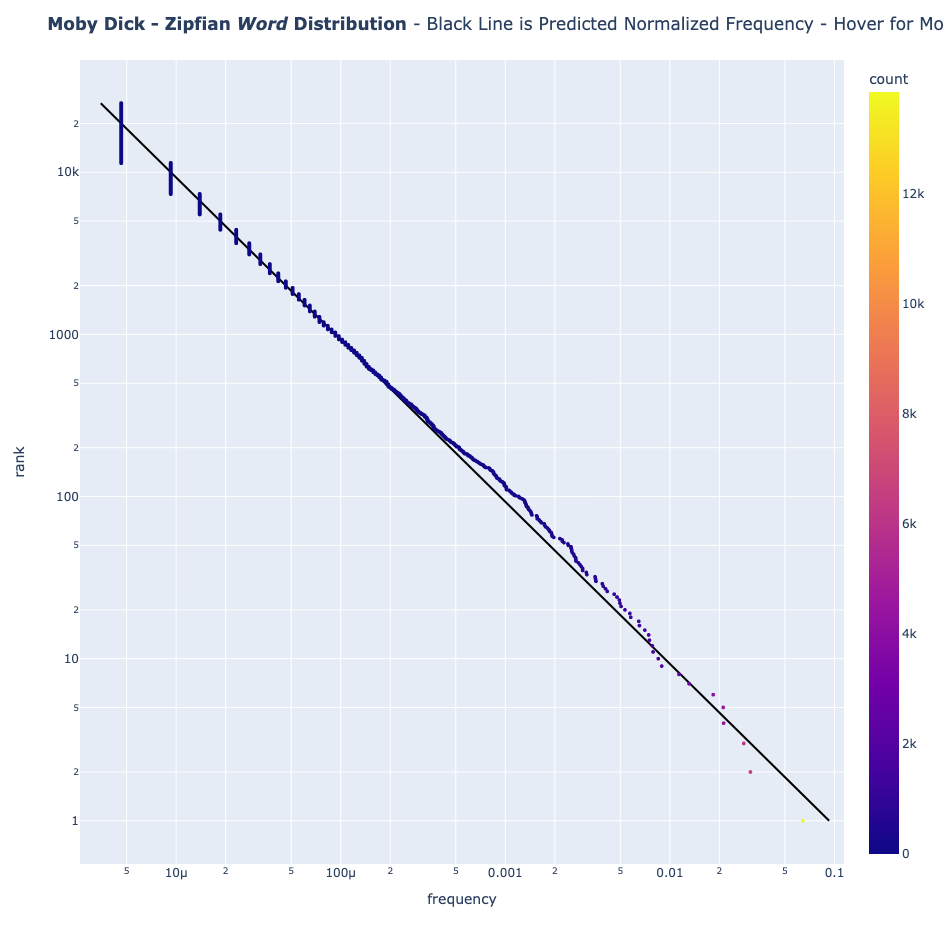
- Spanish (El Espía del Inka)
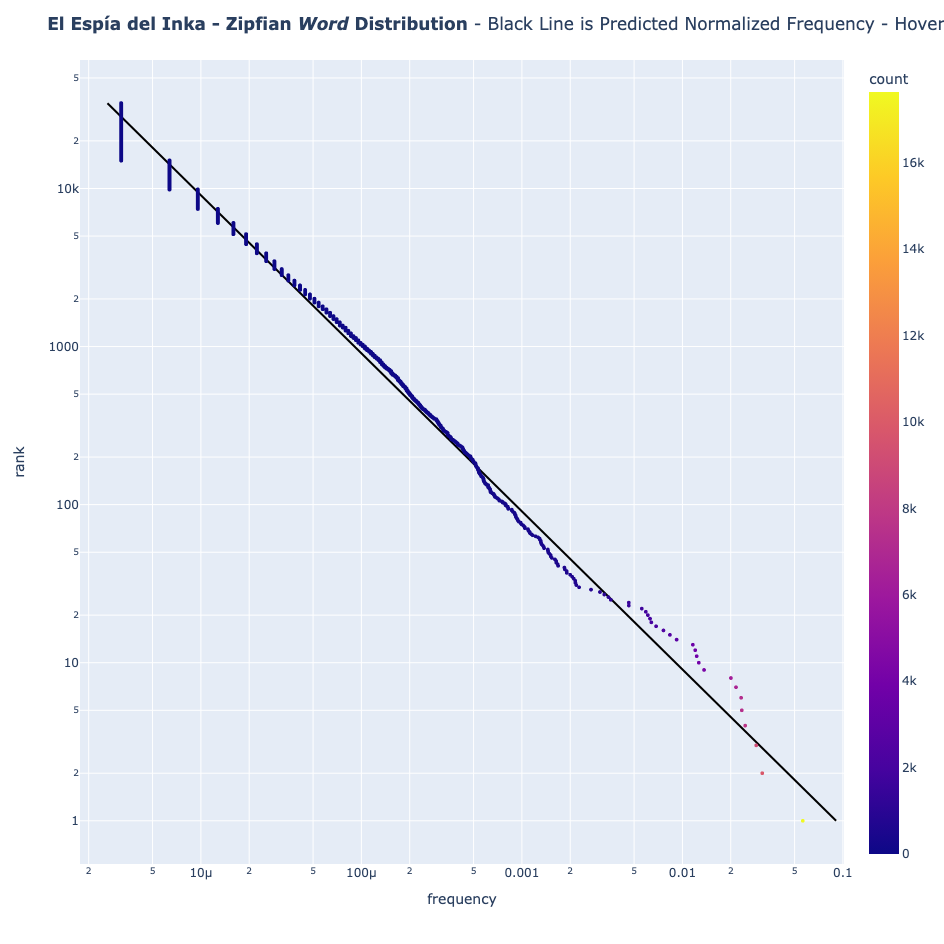
- Quechua (New Testament)
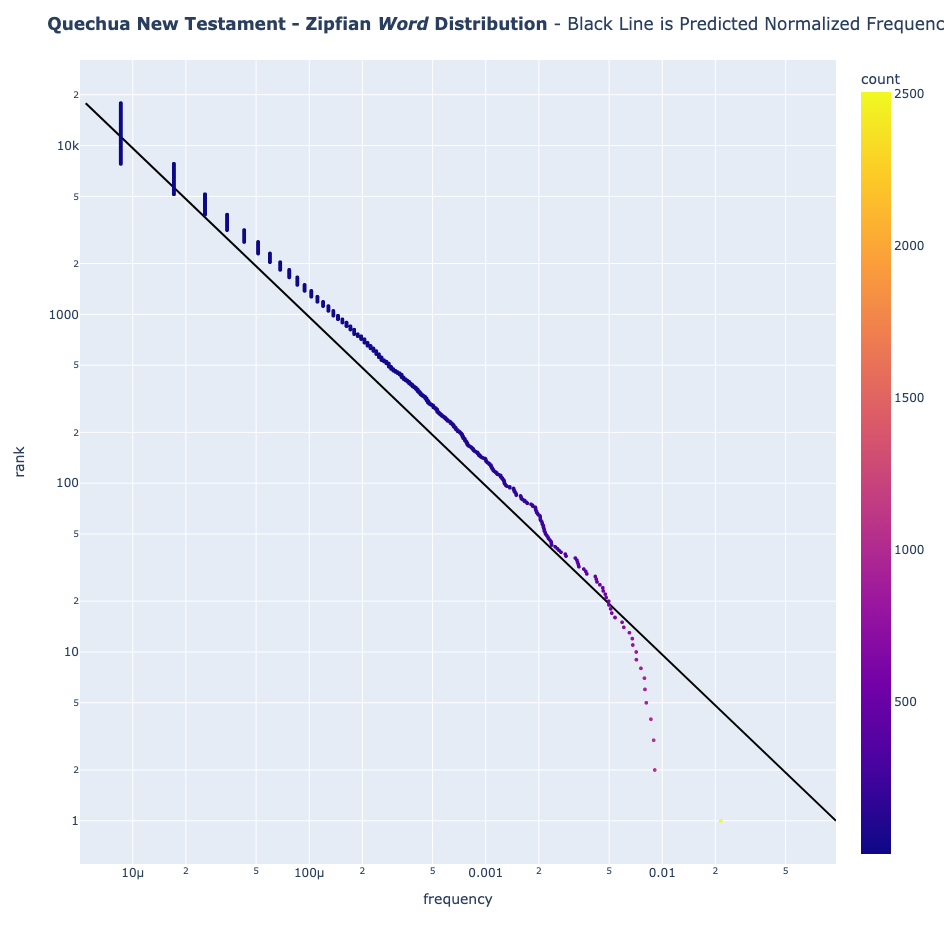
And then I tested it for khipu:
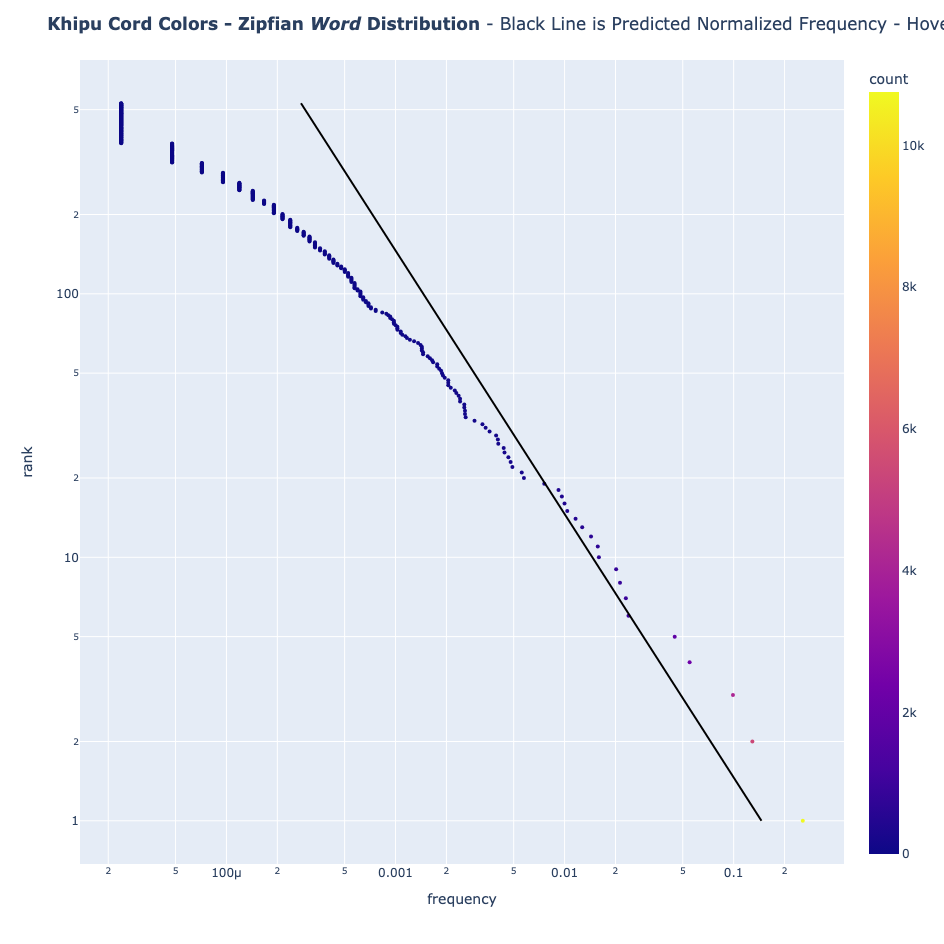
- Cord colors
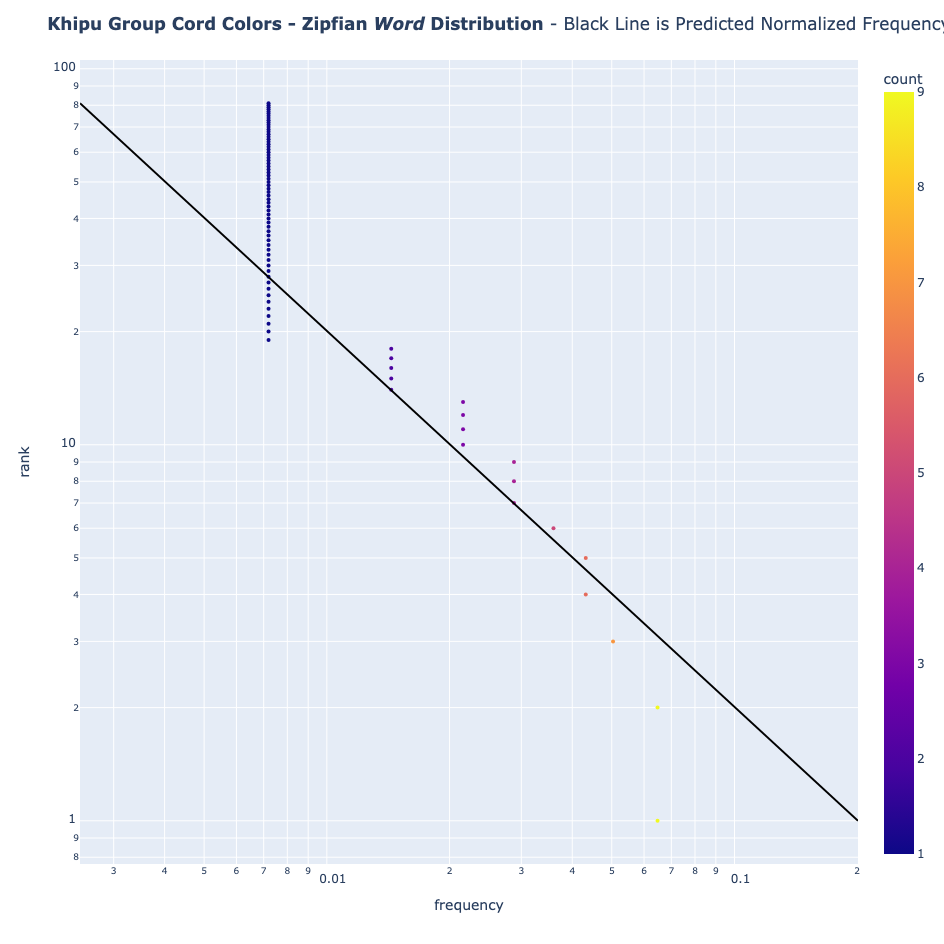
- Cord-group colors
- Cord values
Natural Languages Follow the Pattern of Zipf's Law
English and Spanish texts follow Zipf's Law beautifully. Even Quechua—though it deviates slightly due to its agglutinative nature (words like "Mamaymanpas" meaning "to-my-mother-also")—still shows the classic Zipfian distribution.
However, Khipus Don't
When we treat khipu elements as "words," none of them follow Zipf's Law properly:
- Cord colors: Wild deviation from expectations, both as single colors, and as color "words" from the set of colors of each khipu group.
- Cord values: Closer to Zipfian distribution, but still a poor fit.
Hapax Legomena
A hapax legomenon (plural hapax legomena) is a word that occurs only once in a manuscript. The term comes from Greek ἅπαξ λεγόμενον (hapax legomenon), meaning “something said once.”
One outcome of Zipf's law is a key feature of natural language—hapax legomena. About 40-60% of words in any text appear only once. This phenomenon was first discovered in the English language by William Kretzschmar, Jr.[6] at Bell Labs in 1958. He analyzed large text corpora computationally—decades before modern linguistics did so routinely — measuring:
- Frequency distributions of words and letters
- Entropy and redundancy of English text
- Predictability of next letters given preceding ones
Kretzchmar discovered that low-rank/low-frequency words have the following types of distributions:
| Corpus | % Hapax Legomona Word Types |
|---|---|
| Typical English text | 40–60% |
| Spoken dialogue | 50–65% |
| Scientific/technical | 25–40% |
Here's how our tests for hapax legomena performed:
|
Text |
% Hapax Legomena |
|
English (Moby Dick) |
~50% |
|
Spanish (El Espía del Inka) |
~50% |
|
Quechua (New Testament) |
~50% |
|
|
|
|
Khipu Cord Values |
~50% ✓ |
|
Khipu Cord Colors |
Too Few Unique Words ✗ |
|
Khipu Group Colors |
Too Many Unique Words ✗ |
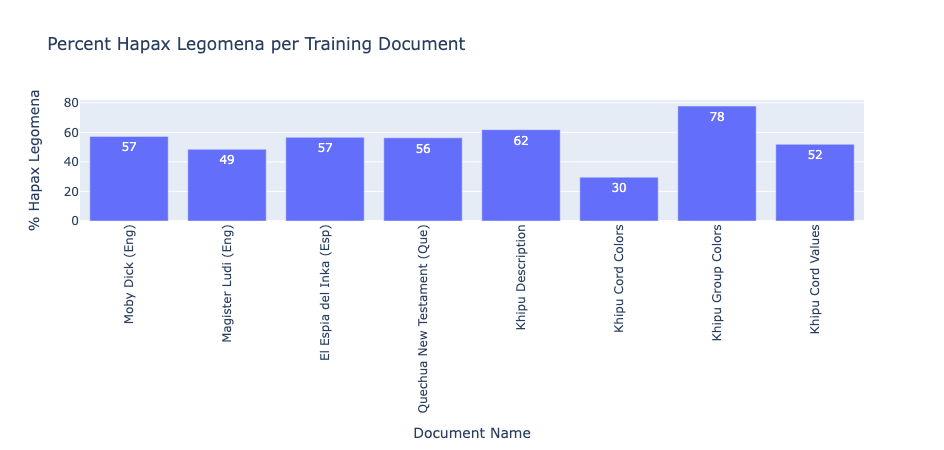
It could be argued that the small amount of data we have in khipus prevents us from achieving a reasonable Zipfian fit for cord colors and values. That would explain the dropoff in low-rank/high-frequency words, but not the erratic fit of high-rank/low-frequency words.
Cord values come closest to natural language expectations. But cord colors? They fail dramatically—likely due perhaps to a limited color palette or small sample size.
The Verdict
The statistical evidence increasingly points to one conclusion: khipus are probably not a written language. They are probably a sophisticated accounting system—possibly the most advanced numerical record-keeping system in the ancient world.
But here's the intriguing caveat: if language exists anywhere in khipus, the data points to one place—the knotted values on the cords themselves, not their colors.
Perhaps khipus were never meant to record speech. Perhaps they were something else entirely: an algebraic language that transcends words.
Foundations of Statistical Natural Language Processing, by Christopher D. Manning, Hinrich Schütze The MIT Press, June 18, 1999 ↩︎
Medrano M, Khosla A. How Can Data Science Contribute to Understanding the Khipu Code? Latin American Antiquity. Published online 2024:1-20. doi:10.1017/laq.2024.5 ↩︎ ↩︎
Pärssinen, Martti ; Kiviharju, Jukka. / Textos andinos : Corpus de textos khipu incaicos y coloniales. Tomo II . Madrid, Helsinki : Instituto Iberoamericano de Finlandia, Universidad Complutense de Madrid, 2010. 473 p. ↩︎
Thompson, Karen M. (2024). A Numerical Connection Between Two Khipus. Ñawpa Pacha, 45(1), 83–104. https://doi.org/10.1080/00776297.2024.2411789 ↩︎
Statistical Universals of Language: Mathematical Chance vs. Human Choice by Kumiko Tanaka-Ishii (Springer-Verlag 2021). ↩︎
William A. Kretzschmar, Jr. 2015. Language and Complex Systems.
Author(s): Edwin Battistella Source: Language and Dialogue, Volume 6, Issue 3, Jan 2016, p. 464 - 469 https://doi.org/10.1075/ld.6.3.06 ↩︎
This post is a synthesis of previous studies in the KhipuFieldGuide. More information can be found on the web pages:
https://www.khipufieldguide.com/notebook/analyses/benford_match.html
https://www.khipufieldguide.com/notebook/analyses/zipfs_law.html

Comments ()